| Issue |
4open
Volume 2, 2019
Statistical Inference in Copula Models and Markov Processes, Case Studies and Insights
|
|
|---|---|---|
| Article Number | 18 | |
| Number of page(s) | 13 | |
| Section | Mathematics - Applied Mathematics | |
| DOI | https://doi.org/10.1051/fopen/2019012 | |
| Published online | 12 June 2019 | |
Research Article
Tail conditional probabilities to predict academic performance
1
Department of Statistics, University of Campinas, Sergio Buarque de Holanda, 651, Campinas, S.P., CEP 13083-859, Brazil
2
University of Campinas, Sergio Buarque de Holanda, 651, Campinas, S.P., CEP 13083-859, Brazil
* Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
10
January
2019
Accepted:
11
April
2019
Abstract
In this paper, we estimate tail conditional probabilities by incorporating copula models and adopting a Bayesian estimation process for the copula’s parameter. Based on the records of student’s classifications in (a) Mathematics and (b) Natural Sciences/Physics (of the entrance exam to the University of Campinas, from 2013 to 2015), by means of tail conditional probabilities we predict the performance, of the same students, in Calculus I which is a mandatory subject of the undergraduate course of Statistics, and we compare the conditional probabilities year after year. We see that (a), (b) and Calculus I show maximal trivariate correlations in tail events given by classifications which are jointly high/low in the three subjects. We compare the evolution of the tail conditional probabilities from 2013 to 2015 and, according to our results there has been an improvement (from 2013 to 2015) of at most 12%. This improvement being more incisive in the settings with conditional events given by jointly high classifications in comparison with settings with conditional events given by jointly lower classifications.
Key words: Directional dependence / Conditional probability / Joe’s copula / Bayesian estimation
© V.A. González-López et al., Published by EDP Sciences, 2019
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1 Introduction
The research based on copula models offers flexibility to represent multivariate structures, since the use of Sklar’s theorem [1] allows us to split the problem of determining the multivariate structure in two stages, (a) with focus on the univariate marginal distributions and (b) with focus on the dependence structure, properly speaking, the copula function. This approach can be very attractive if stage (a) is simplified by characteristics of the real problem. In this paper we point to this situation, since the observed values are relevant in relation to the positions they take in the sample (their ranks). The models of copula allow to incorporate to the study a great diversity of types of dependence. Despite the enormous flexibility offered by the copulas they are not free from the limitations imposed by small or moderate data sets and, for such situations, alternative approaches make sense, such as adopting a Bayesian perspective or a non-parametric perspective based on, for instance, the ranks of the observations. In this paper, we conduct a trivariate dependence study and our focus is to inspect conditional probabilities estimated by the copula. More precisely, our object of inspection are probabilities in the tails, close to the extreme values, for which copulas are especially useful. The copula has a domain given by the cartesian product of several intervals [0, 1], it scales the observed values to this domain and thus, transforms the extreme values of the original observations into values close to 0 and 1. We base the trivariate study on a type of copula with bivariate and non-negative Spearman’s coefficients. From the bivariate and uniparametric model introduced in [2] (family 2.8) using the mixture representation (theorem 4.6.2 in [3]) we extend the model to the trivariate case. With these tools we inspect data from students of the University of Campinas, all of them selected for the undergraduate course of Statistics, with entrance in 2013, 2014 and 2015 respectively. The database is composed by two scores related to the section of the entrance exam that evaluates exact sciences. The dataset also records the scores obtained by these students in Calculus I (subject of the first period in the course). In this paper, we create a representation for the predictive power that the specific topics of the entrance exam have as to predict the performance in Calculus I. That is, we model and compare the 3 years looking for subsidies that allow us to answer if there has been an improvement in the predictive capacity of those topics of the entrance exam, as the years go by. This question is especially relevant from 2014 to 2015, when happened a revision of the topics evaluated by the entrance exam.
In Section 2, we discuss the preliminary concepts to deal with trivariate analysis, as is the case. In Section 3, we introduce the problem and perform an inspection of the database. In Section 4, we introduce the model to be estimated and the connection with the tail probabilities that we will estimate. Also, in Section 4, we introduce the estimators of those probabilities. The general conclusions are given in Section 5.
2 Preliminaries
Given a pair of random variables (X
1, X
2) with cumulative 2-distribution H and marginal distributions F
i
, i = 1, 2, i.e. ∀x, F
1 (x) = H(x,∞) and F
2 (x) = H(∞, x), there exists a cumulative distribution C:[0, 1]2→[0, 1] with Uniform marginal distributions ![Mathematical equation: $ (C(u,1)=u,\enspace C(1,u)=u,\enspace \forall u\in [\mathrm{0,1}])$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq1.gif) such that,
such that, 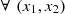 value of (X
1, X
2),
value of (X
1, X
2),
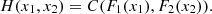 (1)
(1)
Then, C is the 2-copula of (X
1, X
2), see [1]. If X
1 and X
2 are continuous the 2-copula is unique, otherwise, C is uniquely determined on the product of ranges Ran F
1 × Ran F
2. This result can be extended for any dimension greater than 2. C represents the dependence between the variables X
1 and X
2. That is, being H the joint distribution between X
1 and X
2, where H results from the composition between C, F
1 and F
2 (see Eq. (1)) while F
i
exposes the marginal law of X
i
(which is not related to X
j
, i ≠ j) C quantifies the relationship between X
1 and X
2. Moreover, it also quantifies the dependence between the variables F
1 (X
1) and F
2 (X
2). As we shall see, dependence coefficients show the copula in its analytical form. Given a pair (X
1, X
2) of continuous random variables with associated 2-copula C, the population version ρ
12 (C) of Spearman’s rho, is  where I = [0, 1]. In the trivariate case, where (X
1, X
2, X
3) is a vector of continuous random variables with 3-copula C, there are several generalizations of Spearman’s rho. They are, (a) the average of the three pairwise measures ρ
12, ρ
13 and ρ
23,
where I = [0, 1]. In the trivariate case, where (X
1, X
2, X
3) is a vector of continuous random variables with 3-copula C, there are several generalizations of Spearman’s rho. They are, (a) the average of the three pairwise measures ρ
12, ρ
13 and ρ
23, 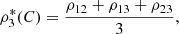 (b) the trivariate generalizations
(b) the trivariate generalizations 
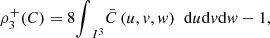 where
where 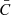 denotes the survival function associated with C, and (c) the coefficients of directional dependence
denotes the survival function associated with C, and (c) the coefficients of directional dependence 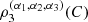 introduced by [4], where
introduced by [4], where  given by
given by  dudvdw, where
dudvdw, where 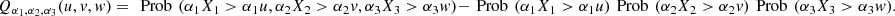 According to [4],
According to [4], 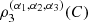 is a linear combination of the pairwise measures and the measures
is a linear combination of the pairwise measures and the measures 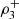 and
and 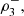 given by
given by 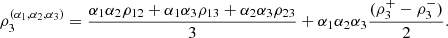 Equivalently,
Equivalently, 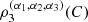 is equal to
is equal to 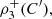 where
where 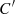 is the copula associated with the random variables (α
1
X
1, α
2
X
2, α
3
X
3). The purpose of the directional ρ-coefficients
is the copula associated with the random variables (α
1
X
1, α
2
X
2, α
3
X
3). The purpose of the directional ρ-coefficients 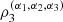 is to detect positive dependence among the random variables X
1, X
2, X
3 undetected by the coefficients
is to detect positive dependence among the random variables X
1, X
2, X
3 undetected by the coefficients  and
and 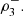 Also note that
Also note that 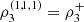 and
and 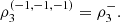 García Jesús et al. [5] proposes to study the following index, with the objective of identifying the highest positive trivariate correlation, among all the possible directions,
García Jesús et al. [5] proposes to study the following index, with the objective of identifying the highest positive trivariate correlation, among all the possible directions,  In [5], is proved that
In [5], is proved that  Suppose that the maximum
Suppose that the maximum  is reached in the direction (−1, −1, 1), this means that the maximum correlation has been given between events type
is reached in the direction (−1, −1, 1), this means that the maximum correlation has been given between events type  and
and  Table 1 shows how to determine the direction which produces the maximal value of
Table 1 shows how to determine the direction which produces the maximal value of 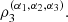
Direction of maximal dependence (sgn denotes the signum function).
Nelsen et al. [4] and García Jesús et al. [5] expose various situations where the coefficients of directional dependence 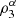 and consequently the index
and consequently the index  are able to capture positive dependence not detected by the traditional 3-variate coefficients
are able to capture positive dependence not detected by the traditional 3-variate coefficients 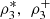 and
and 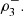 Also, in the next subsection we will give an example in which is evident the usefulness of the coefficients of directional dependence.
Also, in the next subsection we will give an example in which is evident the usefulness of the coefficients of directional dependence.
All these coefficients are estimated from the ranks of the observations, as we will see below.
2.1 Estimation of coefficients
Consider a trivariate random sample 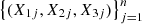 of the vector (X
1, X
2, X
3) with associated unknown copula C. Let be R
ij
= rank of X
ij
in
of the vector (X
1, X
2, X
3) with associated unknown copula C. Let be R
ij
= rank of X
ij
in 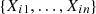 and define
and define 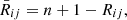 for i = 1, 2, 3. The nonparametric estimators are
for i = 1, 2, 3. The nonparametric estimators are 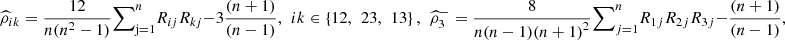
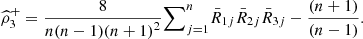 Set
Set  to be R
ij
if α
i
= −1 and
to be R
ij
if α
i
= −1 and 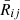 if α
i
= 1, and define the estimator of the coefficient of directional dependence
if α
i
= 1, and define the estimator of the coefficient of directional dependence 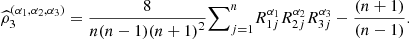 The plug-in estimator of
The plug-in estimator of 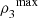 is given by
is given by 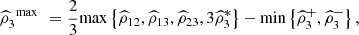 where
where 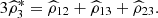
In the following example we show how the directional ρ coefficients summarize in one number the dependence behavior in a trivariate random vector. For instance, between two variables we can observe concordance (both growing) or discordance (one growing and the other not) and in the trivariate case we can have combinations of those situations.
Example 2.1
The data is coming from [6], it is part of the dataset Intercountry Life-Cycle Savings Data which are averaged over the decade 1960–1970. It is composed by n = 50 observations of two demographic variables (i) the percentage of population less than 15 years old and (ii) the percentage of the population over 75 years old and one economic variable (iii) the per-capita disposable income, coming from the countries: Australia, Austria, Belgium, Bolivia, Brazil, Canada, Chile, China, Colombia, Costa Rica, Denmark, Ecuador, Finland, France, Germany, Greece, Guatamala, Honduras, Iceland, India, Ireland, Italy, Japan, Korea, Luxembourg, Malta, Norway, Netherlands, New Zealand, Nicaragua, Panama, Paraguay, Peru, Philippines, Portugal, South Africa, South Rhodesia, Spain, Sweden, Switzerland, Turkey, Tunisia, United Kingdom, United States, Venezuela, Zambia, Jamaica, Uruguay, Libya, Malaysia.
In
Table 2
, we report all the coefficient’s estimates. We see that
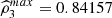 exposes a positive and marked value. Note, on the other hand, that none of the traditional trivariate coefficients
exposes a positive and marked value. Note, on the other hand, that none of the traditional trivariate coefficients
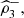
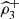 or
or
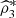 detect positive dependence. Even more, only one of the pair coefficients (
detect positive dependence. Even more, only one of the pair coefficients (
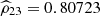 ) shows a positive value, as is evident from the inspection of
Figure 2a
. In
Figure 2b
, the scale of colors goes from red to black when the values in the axis “pop75” grows. In red the smaller values and in black the highest ones, going through a red-black color. This attribute is exercised by the option “highlight.3d” of the function “scatterplot3d” from the “Scatterplot3d” package of R-project.
) shows a positive value, as is evident from the inspection of
Figure 2a
. In
Figure 2b
, the scale of colors goes from red to black when the values in the axis “pop75” grows. In red the smaller values and in black the highest ones, going through a red-black color. This attribute is exercised by the option “highlight.3d” of the function “scatterplot3d” from the “Scatterplot3d” package of R-project.
Estimators of the coefficients. (i) percentage of population less than 15 years old (code 1), (ii) percentage of the population over 75 years old (code 2) and (iii) per-capita disposable income (code 3).
Table 3
shows in which situation this data is found, among those detailed in
Table 1
. We see that the variables pop75 and dpi are concordant, in the sense shown in
Figure 2a
, while each one of them is discordant with pop15, as seen in
Figure 1
. Thus, it is expected that the maximum dependence occurs in α = (1, −1, −1) and α = (−1, 1, 1). In
Figure 3
, we show the scatterplots between the margial ranks of the three original variables (on (a)) and those variables oriented in the direction of the maximal dependence (1, −1, −1) (on (b)). Note that this means that

 |
Figure 1 (a) Percentage of population less than 15 years old (pop15) vs. percentage of the population over 75 years old (pop75). (b) Percentage of population less than 15 years old (pop15) vs. per-capita disposable income (dpi). Observations of n = 50 countries (see [6]). |
 |
Figure 2 (a) Percentage of the population over 75 years old (pop75) vs. per-capita disposable income (dpi). (b) Scatterplot between pop15, pop75 and dpi, from red to black color in increasing order in relation to the “pop75” axis. Observations of n = 50 countries (see [6]). |
 |
Figure 3 (a) Scatterplot between ranks of pop15, ranks of pop 75 and ranks of dpi, from red to black color in increasing order in relation to the “ranks of pop75” axis. (b) Scatterplot between ranks of pop15, – ranks of pop 75 and – ranks of dpi, since |
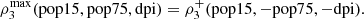
Direction of maximal dependence: (i) percentage of population less than 15 years old (code 1), (ii) percentage of the population over 75 years old (code 2) and (iii) per-capita disposable income (code 3).
Number of observations by year.
In this way, the maximum trivariate dependence occurs in events of type:
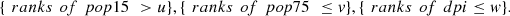
In some situations like the one investigated in this work, given the meaning of the variables, it is expected that the maximal dependence will hold a specific behavior, occurring in certain directions, and the maximal dependence index  allows to verify whether this actually happens or not. For example, if a whole concordance is expected, in all variables of the vector, the maximum dependence must occur in the directions (1, 1, 1) and/or (−1, −1, −1), corresponding with a maximal dependence detected by the coefficients
allows to verify whether this actually happens or not. For example, if a whole concordance is expected, in all variables of the vector, the maximum dependence must occur in the directions (1, 1, 1) and/or (−1, −1, −1), corresponding with a maximal dependence detected by the coefficients 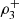 and/or
and/or 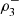 .
.
3 Assessment of recruitment system
The University of Campinas (Unicamp) is one of the three most recognized public universities in the state of São Paulo in Brazil, these are: Unesp (São Paulo State University), Unicamp and USP (University of São Paulo). Unicamp is responsible for about 15% of the country’s scientific production, offering graduate courses, undergraduate courses and technical high schools courses. The institution offers about 70 undergraduate courses in the most diverse areas of knowledge, each course offers a specific number of places per year. Candidates are selected through an evaluation process in different areas of knowledge and certain subjects are more relevant than others to achieve the necessary score for the admission in a specific course. This is the case of the Statistics undergraduate course inserted in the exact sciences. The entrance exam during the period 2013–2015 was composed of a first phase of various general knowledge areas and two writings. And a second phase constituted in 2013 and 2014 by specific tests in (i) Writing (ii) Mathematics, (iii) Portuguese, (iv) Humanities and Arts, (v) English and (vi) Natural Sciences. In 2015, (iv) and (vi) were split in (a) Physics, (b) Biology, (c) Chemistry, (d) History and (e) Geography. For the undergraduate course of Statistics the most relevant disciplines in the 2013–2014 versions are: Mathematics and Natural Sciences and for 2015, Mathematics and Physics. An assumption that is used as the basis for the conception of the entrance exams in this format is that certain subjects of the entrance exam could measure the ability of a student in relation to some subjects of the course. For example, a student of the undergraduate course of Statistics should take lessons of calculus, analysis, algebra, etc, and in that case mathematics and natural sciences (or physics), of the entrance exam, would be potential predictors of performance in those subjects. And that may be one of the reasons why the entrance exam has been modified from 2014 to 2015.
In this paper, we implement a trivariate study that involves the Calculus I subject of the undergraduate course in Statistics (taken at the begin of the course) and two subjects of the entrance exam: for 2013 and 2014 (1) Mathematics and (2) Natural Sciences and for 2015 (1) Mathematics and (2) Physics. We wish to estimate the probability that, given a poor performance in (1) and (2), a poor performance occurs in Calculus I, and we also want to estimate the probability that, given an efficient performance in (1) and (2), the performance in Calculus I be efficient. We would also like to evaluate if the alteration occurred from 2014 to 2015 in the entrance examination caused positive modifications in this regard. That is, we expect an increase in such probabilities.
3.1 Data set
The database is composed of annual trivariate data of students of the undergraduate course in Statistics at Unicamp, corresponding to three consecutive years: 2013, 2014 and 2015 and involving two subjects of the entrance examination of Unicamp and the subject of Calculus I, the latter already being studied during the course in Statistics at Unicamp. We have considered the two most related subjects with exact sciences and that made part of the group of subjects evaluated in the entrance examination, in 2013 and 2014 these are: Mathematics and Natural Sciences. Already for 2015, the entrance exam was modified, and the two subjects most related to Calculus I are: Mathematics and Physics, see Figures 4–6. In this paper, the Calculus I grades are identified with the variable X 1 , the Mathematics (of the entrance exam) with X 2 and depending on the year, X 3 represents Natural Sciences or Physics.
 |
Figure 4 Data of 2013. (a) Scatterplot between Calculus I, Mathematics and Natural Sciences, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Natural Sciences, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
 |
Figure 5 Data of 2014. (a) Scatterplot between Calculus I, Mathematics and Natural Sciences, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Natural Sciences, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
 |
Figure 6 Data of 2015. (a) Scatterplot between Calculus I, Mathematics and Physics, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Physics, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
We see, from Table 5, that the directions of maximal dependence follow the expected trend. That is, we expect a greater concentration of the dependence in the directions (1, 1, 1) and (−1, −1, −1) which would indicate that large 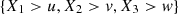 or low
or low  grades capture the highest correlation.
grades capture the highest correlation.
Estimation of coefficients. On the left the bivariate Spearman’s rho coefficients (in bold letter the largest), on the right the trivariate correlations (in bold letter the largest), α m shows the direction of maximal dependence. Calculus I (subscript 1), Mathematics (subscript 2) and Natural Sciences or Physics (subscript 3).
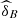
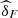
In 2013 and 2015 the maximum dependence occurs in the direction (−1, −1, −1), while in 2014 the maximum dependence occurs in the direction (1, 1, 1). For each year the magnitude of the directional dependencies 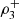 and
and 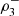 is similar. Remarkable is the low and maximal 3-variate directional correlation (
is similar. Remarkable is the low and maximal 3-variate directional correlation (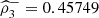 ) observed in 2013.
) observed in 2013.
To compute the probabilities that we want, we will take into account the dependence between the three variables. For such we appeal to the notion of copula that will allow us to model this dependence.
4 Dependence and tail probabilities
Returning to the context of equation (1) in the trivariate case, we define (U 1, U 2, U 3) := (F 1 (X 1),F 2 (X 2),F 3 (X 3)) that is, that each variable X i is transformed into F i (X i ). Given that F i is the cumulative distribution of X i , X i is subjected to a non-decreasing monotonic transformation. Each marginal F i rescales X i to [0, 1] which allows inserting the three variables in the same spectrum of variability. The joint distribution between U 1, U 2 and U 3 is the copula referenced in equation (1). Our purpose to follow is to formulate an adequate construction of C for (U 1, U 2, U 3), which will lead us to adopt the trivariate Joe’s copula in data modeling.
As we have already observed, the Spearman’s rho coefficientes in the current study assume positive values, which leads us to consider models that respect this condition. One of the bivariate models of considerable flexibility and easy interpretation is that given by the copula introduced in [2] (bivariate Joe’s copula), whose properties are widely investigated in [2] and [3]. The most striking property is that as the Spearman’s rho coefficiente increases, the value of the parameter that indexes the bivariate model also increases, and vice versa. The bivariate version covers from the independence case (C(u,v) = uv) to the extreme positive dependence case (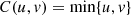 ). The copula model presented below is a generalization of [2] and will be formulated by means of an Archimedean generator. The bivariate family is
). The copula model presented below is a generalization of [2] and will be formulated by means of an Archimedean generator. The bivariate family is
![Mathematical equation: $$ C(u,v|\delta )=1-\{{\bar{u}}^{\delta }+{\bar{v}}^{\delta }-{\bar{u}}^{\delta }{\bar{v}}^{\delta }{\}}^{\frac{1}{\delta }},\enspace 1\le \delta < \infty,\enspace \bar{u}=1-u,\bar{v}=1-v,\enspace u,v\in \left[\mathrm{0,1}\right]. $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq62.gif) (2)
(2)
A simple way to extend this model to dimension 3 is by considering the fact that (2) is an Arquimedian copula, and therefore can be constructed from an Arquimedian generator. That is, in the case of the model (2) the generator is ![Mathematical equation: $ \phi (t)=-\mathrm{ln}(1-[1-t{]}^{\delta }),\enspace \delta \in [1,\mathrm{\infty })$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq63.gif) then,
then,  with
with ![Mathematical equation: $ {\phi }^{-1}(s)=1-[1-{e}^{-s}{]}^{\frac{1}{\delta }}.$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq65.gif) Since ϕ is a continuous strictly decreasing function from [0, 1] to [0, ∞] such that ϕ(0)=∞ and ϕ(1) = 0,
Since ϕ is a continuous strictly decreasing function from [0, 1] to [0, ∞] such that ϕ(0)=∞ and ϕ(1) = 0,
![Mathematical equation: $$ \begin{array}{cc}C(u,v,w|\delta )={\phi }^{-1}(\phi (u)+\phi (v)+\phi (w)),\enspace & u,v,w\in [\mathrm{0,1}]\end{array} $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq66.gif) (3)is also a copula (see Thm. 4.6.2 in [3]). Naturally this way of constructing copulas can be extended to dimensions greater than 3. Note that the bivariate marginal cumulatives derived from (3) are bivariate copulas type (2), for instance
(3)is also a copula (see Thm. 4.6.2 in [3]). Naturally this way of constructing copulas can be extended to dimensions greater than 3. Note that the bivariate marginal cumulatives derived from (3) are bivariate copulas type (2), for instance 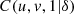 of equation (3) is equal to
of equation (3) is equal to 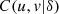 of equation (2). So, the 3-copula is given by
of equation (2). So, the 3-copula is given by
![Mathematical equation: $$ C(u,v,w|\delta )=1-\{1-\left(1-{\bar{u}}^{\delta }\right)\left(1-{\bar{v}}^{\delta }\right)\left(1-{\bar{w}}^{\delta }\right){\}}^{\frac{1}{\delta }},\enspace \bar{u}=1-u,\bar{v}=1-v,\bar{w}=1-w,\enspace u,v,w\in \left[\mathrm{0,1}\right]. $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq69.gif)
As the annual database is compound by around 60 observations (see Tab. 4), it seems reasonable to maintain only one parameter δ in the formulation of the model. 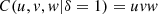 is the 3-copula of independence and when the value of δ is near to one, strongest is the evidence of joint independence, between the variables. The estimation of the parameter of the copula allows the construction of conditional probabilities which make possible the inspection of the dependence’s impact in the tail probability year after year. More precisely, if we want to estimate
is the 3-copula of independence and when the value of δ is near to one, strongest is the evidence of joint independence, between the variables. The estimation of the parameter of the copula allows the construction of conditional probabilities which make possible the inspection of the dependence’s impact in the tail probability year after year. More precisely, if we want to estimate 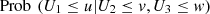 and
and  we can use the following relationships:
we can use the following relationships:
 (4)
(4)
Since,
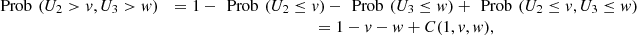 (5)and
(5)and
![Mathematical equation: $$ \begin{array}{cc}\mathrm{Prob}\enspace ({U}_1>u,{U}_2>v,{U}_3>w)& =\enspace \mathrm{Prob}\enspace ({U}_1>u)-\enspace \mathrm{Prob}\enspace ({U}_1>u,{U}_2\le v)-\enspace \mathrm{Prob}\enspace ({U}_1>u,{U}_3\le w)+\enspace \mathrm{Prob}\enspace ({U}_1>u,{U}_2\le v,{U}_3\le w)\\ & =1-u-[\enspace \mathrm{Prob}\enspace ({U}_2\le v)-\enspace \mathrm{Prob}\enspace ({U}_1\le u,{U}_2\le v)]-[\enspace \mathrm{Prob}\enspace ({U}_3\le w)-\enspace \mathrm{Prob}\enspace ({U}_1\le u,{U}_3\le w)]+[\enspace \mathrm{Prob}\enspace ({U}_2\le v,{U}_3\le w)-\enspace \mathrm{Prob}\enspace ({U}_1\le u,{U}_2\le v,{U}_3\le w)]\\ & =1-u-v-w+C(u,v,1)+C(u,1,w)+C(1,v,w)-C(u,v,w),\end{array} $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq75.gif) (6)from (5) and (6), we obtain
(6)from (5) and (6), we obtain
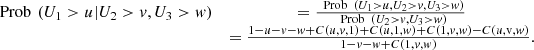 (7)
(7)
In Figure 7 we see the trend of the conditional probabilities (4) and (7), for Joe’s model (Eq. (3)). In both cases as the δ value increases so do the conditional probabilities. This characteristic is related to the connection between the δ parameter and the Spearman’s rho coefficient, which grows as δ grows. For instance,  (corresponding to ρ
12=0) and, when δ grows
(corresponding to ρ
12=0) and, when δ grows 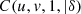 tends to
tends to  (corresponding to ρ
12 = 1). Equivalently it happens for the other combinations of variables two to two, of U
1, U
2 and U
3.
(corresponding to ρ
12 = 1). Equivalently it happens for the other combinations of variables two to two, of U
1, U
2 and U
3.
 |
Figure 7 (a) |
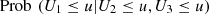
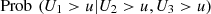
We note that the quantities (4) and (7) (for values close to u = v = w = 0 and u = v = w = 1, respectively) are the ones that should grow from 2013 to 2015, according to what is expected, if there has been an increase in the predictive capacity of the entrance exam. Proximity to zero refers to low grades and poor performance and proximity to one refers to high grades and efficient performance.
Setting an interval for U 2 and U 3, let’s say [a, b], we can compute the probability of U 1 being less than or equal to u. This computation allows us to quantify the effect of U 2 and U 3 on U 1. So,
![Mathematical equation: $$ \mathrm{Prob}\enspace ({U}_1\le u|{U}_2\in [a,b],{U}_3\in [a,b])=\frac{C(u,b,b)+C(u,a,a)-C(u,a,b)-C(u,b,a)}{C(1,b,b)+C(1,a,a)-C(1,a,b)-C(1,b,a)} $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq80.gif) (8)and in a complementary way
(8)and in a complementary way
![Mathematical equation: $$ \mathrm{Prob}\enspace ({U}_1>u|{U}_2\in [a,b],{U}_3\in [a,b])=1-\enspace \mathrm{Prob}\enspace ({U}_1\le u|{U}_2\in [a,b],{U}_3\in [a,b]). $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq81.gif) (9)
(9)
An inspection of this quantities could provide an estimate of the expected range of the conditional probability, given an interval [a, b] and a threshold of interest u.
4.1 Estimation
In this section we discuss the estimation process. The values observed annually 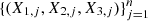 will be transformed by their marginal ranks re-scaled to [0, 1], with n given by Table 4, year by year. In this way, the triples
will be transformed by their marginal ranks re-scaled to [0, 1], with n given by Table 4, year by year. In this way, the triples 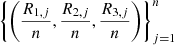 represent the values of (U
1, U
2, U
3). Then, U
1 are the ranks of the grades in Calculus I scaled to [0, 1], U
2 are the ranks of the grades of Mathematics scaled to [0, 1] and U
3 are the ranks of the grades of Natural Sciences (2013–2014) or Physics (2015) scaled to [0, 1]. Note also that working with ranks turn the data comparable, even though the entrance exam applied is different each year.
represent the values of (U
1, U
2, U
3). Then, U
1 are the ranks of the grades in Calculus I scaled to [0, 1], U
2 are the ranks of the grades of Mathematics scaled to [0, 1] and U
3 are the ranks of the grades of Natural Sciences (2013–2014) or Physics (2015) scaled to [0, 1]. Note also that working with ranks turn the data comparable, even though the entrance exam applied is different each year.
From equation (3), it is possible to derive the density of the copula, say 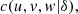 and to implement the process of estimating the parameter (δ). In the present case we give space to a Bayesian procedure, since the annual database shows a moderate size (Tab. 4). We assume a non-informative priori distribution on δ, that is, π(δ) ∝ k (constant value), then the posteriori distribution of δ is proportional to the likelihood.
and to implement the process of estimating the parameter (δ). In the present case we give space to a Bayesian procedure, since the annual database shows a moderate size (Tab. 4). We assume a non-informative priori distribution on δ, that is, π(δ) ∝ k (constant value), then the posteriori distribution of δ is proportional to the likelihood.
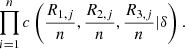 (10)
(10)
Under quadratic loss function, the Bayesian estimator is the mean of the posterior distribution of δ, and this will be the estimator  obtained by Importance Sampling (see [7]). For comparison we have also registered the frequentist estimators, we adopted the semiparametric method suggested in [8]. Thus,
obtained by Importance Sampling (see [7]). For comparison we have also registered the frequentist estimators, we adopted the semiparametric method suggested in [8]. Thus, 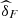 denotes the estimates obtained by maximization of the pseudo-loglikelihood, given by equation (11)
denotes the estimates obtained by maximization of the pseudo-loglikelihood, given by equation (11)
![Mathematical equation: $$ \sum_{i=1}^n \mathrm{ln}\left[c\left(\frac{{R}_{1,j}}{n},\frac{{R}_{2,j}}{n},\frac{{R}_{3,j}}{n}|\delta \right)\right]. $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq88.gif) (11)
(11)
The classical estimators 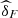 were obtained by the function fitCopula (method mpl) available in the R package Copula from R project for Statistical Computing (see https://cran.r-project.org/web/packages/copula/copula.pdf).
were obtained by the function fitCopula (method mpl) available in the R package Copula from R project for Statistical Computing (see https://cran.r-project.org/web/packages/copula/copula.pdf). 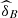 is the Bayesian estimator of the expected value,
is the Bayesian estimator of the expected value,
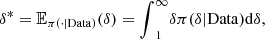 (12)where
(12)where  is the posterior density of δ and δ ≥ 1. By Importance Sampling and knowing the posterior density
is the posterior density of δ and δ ≥ 1. By Importance Sampling and knowing the posterior density 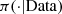 we choose a density q(·) from what is easy to generate values of δ, say δ
1, …, δ
m
and we can define the approximation of equation (12) by,
we choose a density q(·) from what is easy to generate values of δ, say δ
1, …, δ
m
and we can define the approximation of equation (12) by,
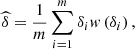 with
with  Since, under regularity conditions
Since, under regularity conditions 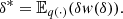 In the present situation we only can access to a function that is proportional to
In the present situation we only can access to a function that is proportional to 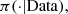 which is given by equation (10) and
which is given by equation (10) and 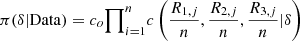 for an unknown contant c
o
. In that case, the self-normalized Importance Sampling estimator of δ
* is given by,
for an unknown contant c
o
. In that case, the self-normalized Importance Sampling estimator of δ
* is given by,
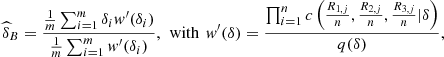 (13)and
(13)and 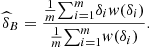 In this case we use as q(·) an exponential density of rate 1 and properly accommodated in the support [1,∞). This function looks appropriate since it attributes zero density to δ < 1. For a description of the quality of the Bayesian estimator (13) see Table 7, where we expose (a) the mean of 1000 replicates of equation (13) and (b) the standard deviation of (a).
In this case we use as q(·) an exponential density of rate 1 and properly accommodated in the support [1,∞). This function looks appropriate since it attributes zero density to δ < 1. For a description of the quality of the Bayesian estimator (13) see Table 7, where we expose (a) the mean of 1000 replicates of equation (13) and (b) the standard deviation of (a).
We see that up to the second decimal position in Table 6 the estimates are consistent with the means in Table 7 (a), reflecting the standard deviation, reported in Table 7 (b).
We note that the value of 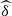 in both versions (
in both versions (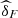 and
and 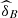 ) grows from 2013 to 2015, showing that the dependence between (U
1, U
2, U
3) grows year by year. This is positive evidence that will have an impact on the conditional probabilities. Using any estimator
) grows from 2013 to 2015, showing that the dependence between (U
1, U
2, U
3) grows year by year. This is positive evidence that will have an impact on the conditional probabilities. Using any estimator 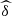 we can define estimations for any operation involving the copula. For instance, following the functional forms of equations (4), (8), (9) and (7), we define
we can define estimations for any operation involving the copula. For instance, following the functional forms of equations (4), (8), (9) and (7), we define
![Mathematical equation: $$ \widehat{\mathrm{Prob}}({U}_1\le u|{U}_2\in [a,b],{U}_3\in [a,b])=\frac{C(u,b,b|\widehat{\delta })+C(u,a,a|\widehat{\delta })-C(u,a,b|\widehat{\delta })-C(u,b,a|\widehat{\delta })}{C(1,b,b|\widehat{\delta })+C(1,a,a|\widehat{\delta })-C(1,a,b|\widehat{\delta })-C(1,b,a|\widehat{\delta })} $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq105.gif) (14)
(14)
![Mathematical equation: $$ \widehat{\mathrm{Prob}}\enspace ({U}_1>u|{U}_2\in [a,b],{U}_3\in [a,b])=1-\enspace \widehat{\mathrm{Prob}}\enspace ({U}_1\le u|{U}_2\in [a,b],{U}_3\in [a,b]). $$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq106.gif) (15)
(15)
For the probabilities in the tails that we want to estimate, we define
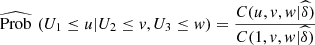 (16)and
(16)and
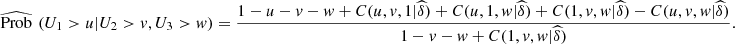 (17)
(17)
The estimates (14) and (15) give us a tool to identify the expected range (2013–2015) of conditional probabilities of the types exposed in equations (8) and (9). In Table 8 we illustrate the values given by the conditional probability of equation (14), for the interval [a, b] = [0.1, 0.2]. We see an increasing order between the lines of the table, from 2013 to 2015.
![Mathematical equation: $ \mathrm{Prob}\enspace ({U}_1\le u|{U}_2\in [\mathrm{0.1,0.2}],{U}_3\in [\mathrm{0.1,0.2}])$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq149.gif)
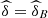
This information allows us to say that if the performance in the subjects of the entrance exam is between 10% and 20% lower, it is to be expected a performance, in Calculus I, below 20% with a probability between 0.29954 and 0.38688.
Table 9 and Figure 8 show the results of equation (15), for [a, b] = [0.8, 0.9] (between 80% and 90%). We see an order in the same sense above, growing from 2013 to 2015, except for values of u close to 1, where the curves are mixed.
![Mathematical equation: $ \mathrm{Prob}\enspace ({U}_1>u|{U}_2\in [\mathrm{0.8,0.9}],{U}_3\in [\mathrm{0.8,0.9}]),\enspace u\in [\mathrm{0,1}]$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq112.gif)

![Mathematical equation: $ \mathrm{Prob}\enspace ({U}_1>u|{U}_2\in [\mathrm{0.8,0.9}],{U}_3\in [\mathrm{0.8,0.9}])$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq151.gif)

Table 10 shows the performance of the conditional probabilities (Eq. (16)) for values u = 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4. See also Figure 9a. We see clearly that the probability increases progressively from 2013 to 2015, but this occurs in a slight way. That is, there was an increase in the capacity to predict low performance in Calculus I, given low performance in the entrance exam (in Mathematics and Natural Sciences/Physics).

![Mathematical equation: $ \mathrm{Prob}\enspace ({U}_1\le u|{U}_2\le u,{U}_3\le u),\enspace u\in [\mathrm{0,1}]$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq114.gif)
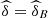
![Mathematical equation: $ \mathrm{Prob}\enspace ({U}_1>u|{U}_2>u,{U}_3>u),\enspace u\in [\mathrm{0,1}]$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq116.gif)
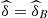
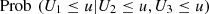
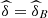
Figure 9b shows that from a value of u (approximately 0.6) the conditional probability (Eq. (17)) increases as u approaches 1. We also note that from 2013 to 2015 these probabilities have increased, but the biggest difference is between 2013 and the other two years (2014 and 2015). Table 11 shows specific values of u, u = 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95 confirming this trend. We perceive an increase in the predictive capacity of a high performance in Calculus I, given high performance in the subjects of the entrance exam, (a) Mathematics and (b) Natural Sciences (in 2013 and 2014) and Physics (in 2015).
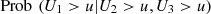
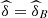
There was then, a gradual improvement in the predictive nature of the subjects of the entrance exam, as we see in Figure 10. In which we show the difference between the curve of 2015 and the curve of 2013, according to equation (16) (to (a)) and according to equation (17) (to (b)).
 |
Figure 10 Estimation of the difference between the conditional probabilities, between 2015 and 2013 with |

![Mathematical equation: $ \mathrm{Prob}{\enspace }_{2015}({U}_1\le u|{U}_2\le u,{U}_3\le u)-\enspace \mathrm{Prob}{\enspace }_{2013}({U}_1\le u|{U}_2\le u,{U}_3\le u),\enspace u\in [\mathrm{0,1}]$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq119.gif)
![Mathematical equation: $ \mathrm{Prob}{\enspace }_{2015}({U}_1>u|{U}_2>u,{U}_3>u)-\enspace \mathrm{Prob}{\enspace }_{2013}({U}_1>u|{U}_2>u,{U}_3>u),\enspace u\in [\mathrm{0,1}]$](/articles/fopen/full_html/2019/01/fopen190007/fopen190007-eq120.gif)
5 Conclusion
In this paper, we explore the analytical skills that copula functions have to estimate conditional probabilities, especially in the tails. By adopting a family such as Joe’s copula (see [2]), it is allowed to embrace a wide range of positive dependencies, incorporated by the δ parameter ranging from δ = 1 (independence) to δ → ∞ (perfect positive dependence). In this paper we address a real problem, in which we want to quantify the ability to predict academic performance in university subjects, based on the performance in subjects/topics of the university entrance exam. We deal with annual data (around 60 observations per year) provided by the University of Campinas (2013, 2014 and 2015). We expect there to be a considerable dependence between the subjects evaluated in the entrance exam and the subjects taken during the university course, mainly in the first year of the course or in the initial educational cycles. Under this assumption we focus our study on a subject of the undergraduate course of Statistics, Calculus I and two subjects of the entrance exam related to the exact sciences: (a) Mathematics (from 2013 to 2015) and (b) Natural Sciences (in 2013 and 2014) and Physics (in 2015). We construct tail conditional probabilities (conditioned on (a) and (b)), with the purpose of inspecting extreme performances (high and low grades of Calculus I). We see that the ability to predict has gradually increased from 2013 to 2015, but this has been happening in a very poor rate. We see in Figure 10 this fact in perspective, the difference between the conditional probabilities, between 2015 (the biggest curve) and 2013 (the lowest curve) is always positive, but of at most 12%. Furthermore, as we approach to u = 0 (low notes) the difference is decreasing, see Figure 10a. And in the same way, as we approach to u = 1 (high notes) this difference is decreasing, but to a lesser degree than in the previous case, see Figure 10b. This means that for low performances there has been a less pronounced improvement than for high performances. This findings could be the result of (a) an entrance exam eventually non tuned with the preliminary notions of Calculus I, (b) very different pedagogical schemes between pre-university studies and university studies, etc. In any of these situations, it may be necessary to carry out a large-scale study and to follow up several versions of the entrance exam, for example of years subsequent to 2015, and also to follow up the performance of these students during the course.
We see in this article how the concept of copula can collaborate for the development of stochastic techniques that allow to follow year after year data bases like the one treated in this occasion. With its implementation, management mechanisms of simple implementation could be developed no requiring large sample sizes, which makes them very dynamic.
Acknowledgments
N. Romano gratefully acknowledge the financial support provided by CAPES with a fellowship of the Master Graduate Program in Statistics – University of Campinas. The authors wish to thank the three referees for their many helpful comments and suggestions on an earlier draft of this paper.
References
- Sklar A (1959), Fonctions de répartition à n dimensions et leurs marges. Publ Inst Statist Univ Paris 8, 229–231. [Google Scholar]
- Joe H (1993), Parametric families of multivariate distributions with given margins. J Multivar Anal 46, 2, 262–282. [CrossRef] [Google Scholar]
- Nelsen RB (2007), An introduction to copulas, Springer Science & Business Media, Berlin, Germany. [Google Scholar]
- Nelsen RB, Úbeda-Flores M (2012), Directional dependence in multivariate distributions. Ann Inst Stat Math 64, 3, 677–685. [CrossRef] [Google Scholar]
- García Jesús E, González-López VA, Nelsen RB (2013), A new index to measure positive dependence in trivariate distributions. J Multivar Anal 115, 481–495. [CrossRef] [Google Scholar]
- Belsley DA, Kuh E, Welsch RE (1980), Regression diagnostics, Wiley, New York, NY. [CrossRef] [Google Scholar]
- Ripley BD (2009), Stochastic simulation, Vol. 316, John Wiley & Sons, New York, NY. [Google Scholar]
- Kim G, Silvapulle MJ, Silvapulle P (2007), Comparison of semiparametric and parametric methods for estimating copulas. Comput Stat Data Anal 51, 6, 2836–2850. [CrossRef] [Google Scholar]
Cite this article as: González-López V.A, Piovesana M.C & Romano N 2019. Tail conditional probabilities to predict academic performance. 4open, 2, 18.
All Tables
Estimators of the coefficients. (i) percentage of population less than 15 years old (code 1), (ii) percentage of the population over 75 years old (code 2) and (iii) per-capita disposable income (code 3).
Direction of maximal dependence: (i) percentage of population less than 15 years old (code 1), (ii) percentage of the population over 75 years old (code 2) and (iii) per-capita disposable income (code 3).
Estimation of coefficients. On the left the bivariate Spearman’s rho coefficients (in bold letter the largest), on the right the trivariate correlations (in bold letter the largest), α m shows the direction of maximal dependence. Calculus I (subscript 1), Mathematics (subscript 2) and Natural Sciences or Physics (subscript 3).
All Figures
|
Figure 1 (a) Percentage of population less than 15 years old (pop15) vs. percentage of the population over 75 years old (pop75). (b) Percentage of population less than 15 years old (pop15) vs. per-capita disposable income (dpi). Observations of n = 50 countries (see [6]). |
| In the text | |
|
Figure 2 (a) Percentage of the population over 75 years old (pop75) vs. per-capita disposable income (dpi). (b) Scatterplot between pop15, pop75 and dpi, from red to black color in increasing order in relation to the “pop75” axis. Observations of n = 50 countries (see [6]). |
| In the text | |
|
Figure 3 (a) Scatterplot between ranks of pop15, ranks of pop 75 and ranks of dpi, from red to black color in increasing order in relation to the “ranks of pop75” axis. (b) Scatterplot between ranks of pop15, – ranks of pop 75 and – ranks of dpi, since |
| In the text | |
|
Figure 4 Data of 2013. (a) Scatterplot between Calculus I, Mathematics and Natural Sciences, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Natural Sciences, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
| In the text | |
|
Figure 5 Data of 2014. (a) Scatterplot between Calculus I, Mathematics and Natural Sciences, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Natural Sciences, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
| In the text | |
|
Figure 6 Data of 2015. (a) Scatterplot between Calculus I, Mathematics and Physics, from red to black color in increasing order in relation to the “Mathematics” axis. (b) Scatterplot between ranks of Calculus I, ranks of Mathematics and ranks of Physics, from red to black color in increasing order in relation to the “Ranks of Mathematics” axis. |
| In the text | |
|
Figure 7 (a) |
| In the text | |
 |
Figure 8
|
| In the text | |
|
Figure 10 Estimation of the difference between the conditional probabilities, between 2015 and 2013 with |
| In the text | |